This project maps rooms with high security scores by overlapping the number of crimes with location data from 2014 to 2019.
The open API of the "Getting a good room with Peter Pan" property sales site is used to scrape room information data in Seoul.
The scraped data is stored as csv, inserted into Elasticsearch using Logstash and Beats from the Elastic Stack, and visualized with Kibana.
In the HTML source of the "Getting a good room with Peter Pan" real estate sales site shown below,
there is a tag indicating the presence or absence of
security facilities.
The goal is to collect this information and compute a security score from it.
<div class="col-md-3 col-xs-4 column left-padding-20">
보안시설
</div>
<div class="col-md-3 col-xs-8 column value">
현관보안, CCTV, 인터폰, 비디오폰, 카드키
</div>
Basic information such as contract type, price, and area was collected from the property sales site.
The tags containing security facility data were then parsed, and a security score was aggregated for each property. The full code related to scraping is available
here.
r_contract = soup.select("div#contract_type")[0].string # 계약형태
r_price = soup.select("tr > td")[5].string.strip() # 가격
r_btype = soup.select("div.column.value")[12].string.strip() # 건물유형
r_area = float(str(soup.select("div.column.value")[15]).split()[5].replace("m2", "")) # 면적
r_security = soup.select(".commonHouse > .row.border-top > .col-md-3.col-xs-8.column.value")\
[1].string.string.strip().replace(" ", "").replace("\n", " ").replace(",", " ").split() # 보안시설
r_sigudong = soup.select("div#sigudong")[0].string # 시구동
r_lat = float(str(soup.select("script")[44].string).split()[77].replace("'", "").replace(";", "")) # 위도
r_long = float(str(soup.select("script")[44].string).split()[81].replace("'", "").replace(";", "")) # 경도
btype = {"아파트": 3, "공동주택": 2, "단독주택": 1}
rsecu = {"자체경비원": 7, "현관보안": 6, "CCTV": 5, "방범창": 4, "인터폰": 2, "비디오폰": 2, "카드키": 1, "-": 0}
r_score = 0 # 보안점수
for j in btype:
if r_btype == j:
r_score = btype[j]
for j in r_security:
r_score += rsecu[j]
r_security = " / ".join(r_security)
info = {"매물번호" : room_info[i],
"계약형태" : r_contract,
"가격정보" : r_price,
"건물유형" : r_btype,
"면적" : r_area,
"보안시설" : r_security,
"보안점수" : r_score,
"시구동" : r_sigudong,
"위도" : r_lat,
"경도" : r_long,
"링크" : ROOM_URL}
peterpan = peterpan.append(info, ignore_index=True)
peterpan.to_csv("dataset/seoul_room.csv", index=False, encoding="utf-8", header=False)
The structure of the scraped data is as follows. It contains the aggregated
security scores, the
security facilities used to calculate each score, and location data given as
latitude and
longitude.
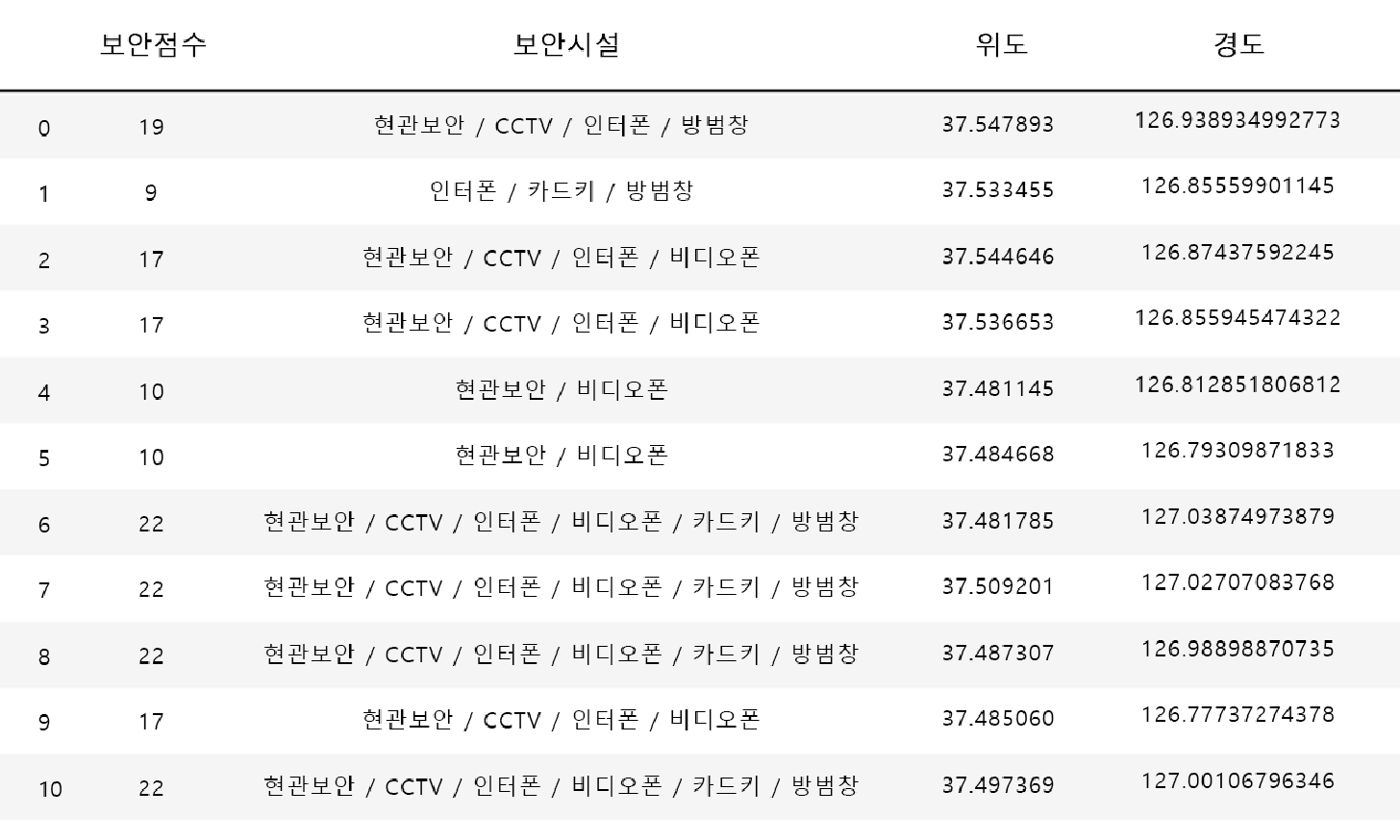 Scraped data saved in CSV format
Scraped data saved in CSV format
Based on the data, a map of the number of crimes in Seoul was created using Kibana.
Hovering the mouse over the map reveals the number of crimes for each area.
The rooms aggregated with security scores were overlapped on the map below so that users could filter out rooms without security facilities.
In addition, the site link containing detailed information about each property was converted from a string type to a URL type, so that users could navigate to the web page through the URL when they selected a room of interest.
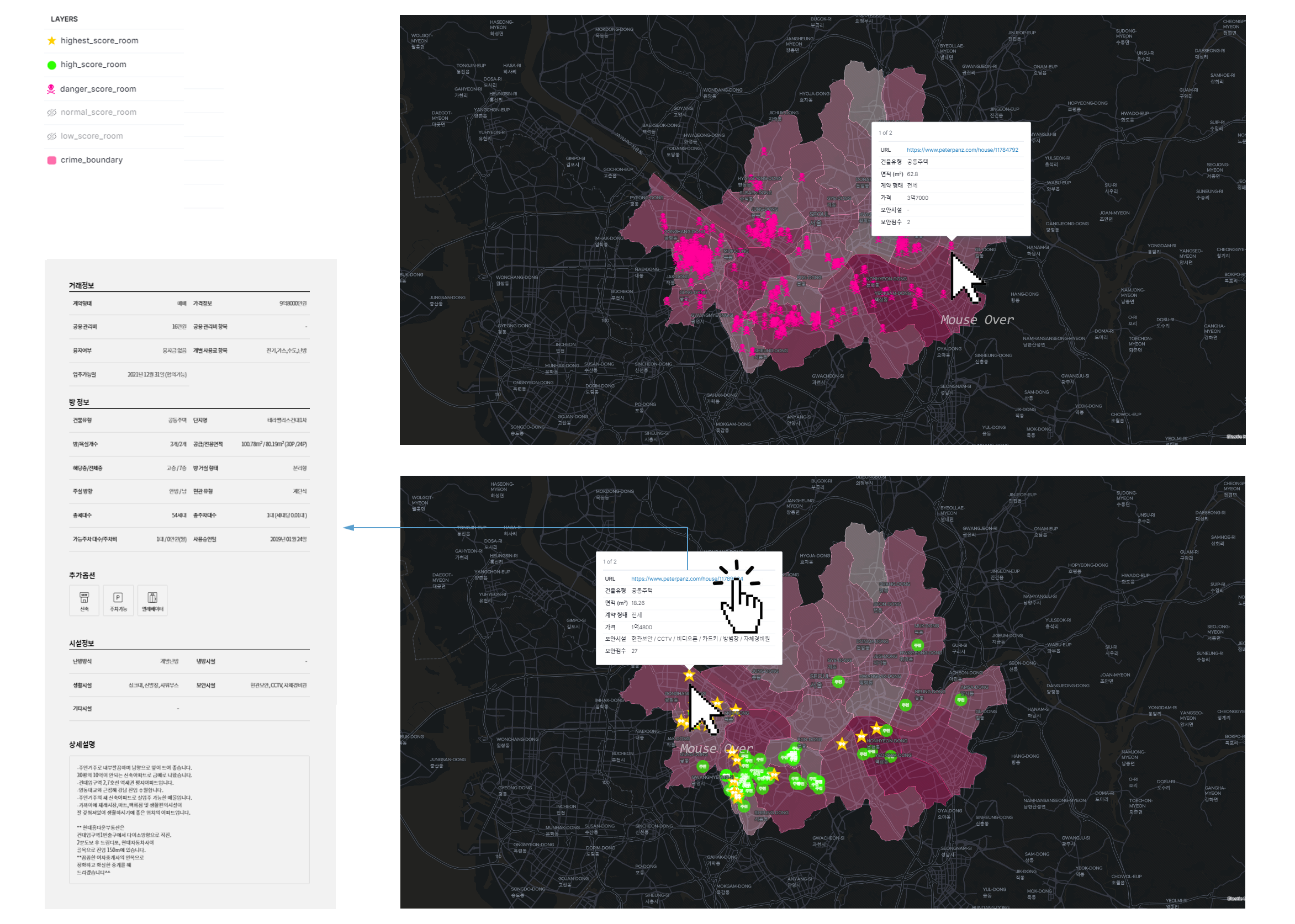 Secure room in Seoul
Secure room in Seoul
From the top, crime score by area · rooms filtered by high security score