This is based on the post
Attention? Attention!
 A Shiba Inu in a men's outfit. The credit of the original photo goes to Instagram
A Shiba Inu in a men's outfit. The credit of the original photo goes to Instagram
@mensweardog.
Given a small patch of an image, pixels in the rest provide clues what should be displayed there.
We expect to see a pointy ear in the yellow box because we have seen a dog's nose, another pointy ear on the right (stuff in the red boxes).
However, the sweater and blanket at the bottom (stuff in the gray boxes) would not be as helpful as those doggy features.
Similarly, we can explain the relationship between words in one sentence or close context.
When we see "eating", we expect to encounter a food word very soon.
Attention in deep learning can be broadly interpreted as a vector of importance weights:
in order to predict or infer one element, such as a pixel in an image or a word in a sentence,
we estimate using the attention vector how strongly it is correlated with (attends to) other elements.
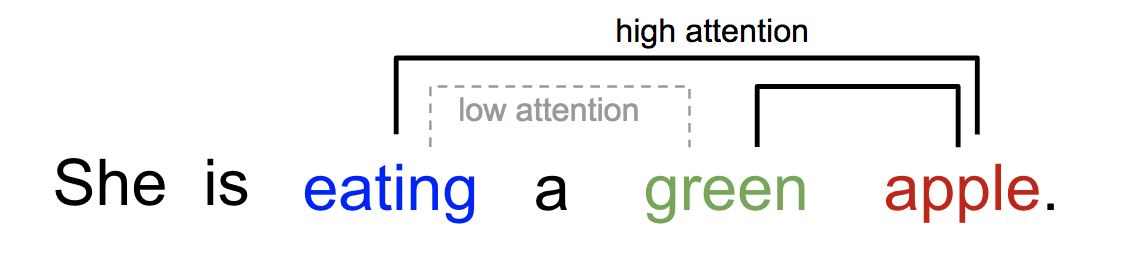 One word "attends" to other words in the same sentence differently.
One word "attends" to other words in the same sentence differently.
The seq2seq model normally has an encoder-decoder architecture, composed of:
-
An encoder processes the input sequence and compresses the information into a context vector of a fixed length.
This representation is expected to be a good summary of the meaning of the whole source sequence.
-
A decoder is initialized with the context vector to emit the transformed output.
The early work only used the last state of the encoder network as the decoder initial state.
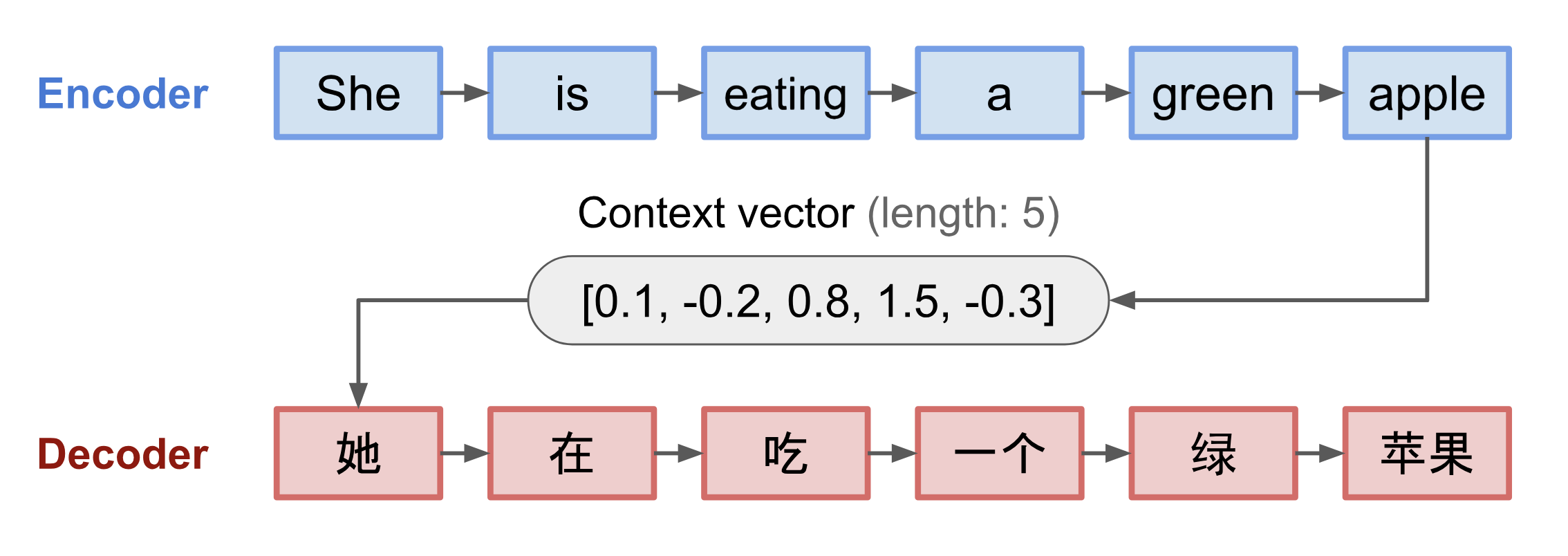 The encoder-decoder model, translating the sentence "she is eating a green apple" to Chinese
The encoder-decoder model, translating the sentence "she is eating a green apple" to Chinese
 An unrolled recurrent neural network diagram taken from
An unrolled recurrent neural network diagram taken from
Understanding-LSTMs
A critical and apparent disadvantage of this fixed-length context vector design
is incapability of remembering long sentences.
Often it has forgotten the first part once it completes processing the whole input.
The attention mechanism was born to resolve this problem.
Rather than building a single context vector out of the encoder's last hidden state,
the secret sauce invented by attention is to create
shortcuts between the context vector and the entire source input.
While the context vector has access to the entire input sequence, we don’t need to worry about forgetting.
The context vector consumes three pieces of information:
-
encoder hidden states
-
decoder hidden states
-
alignment between source and target
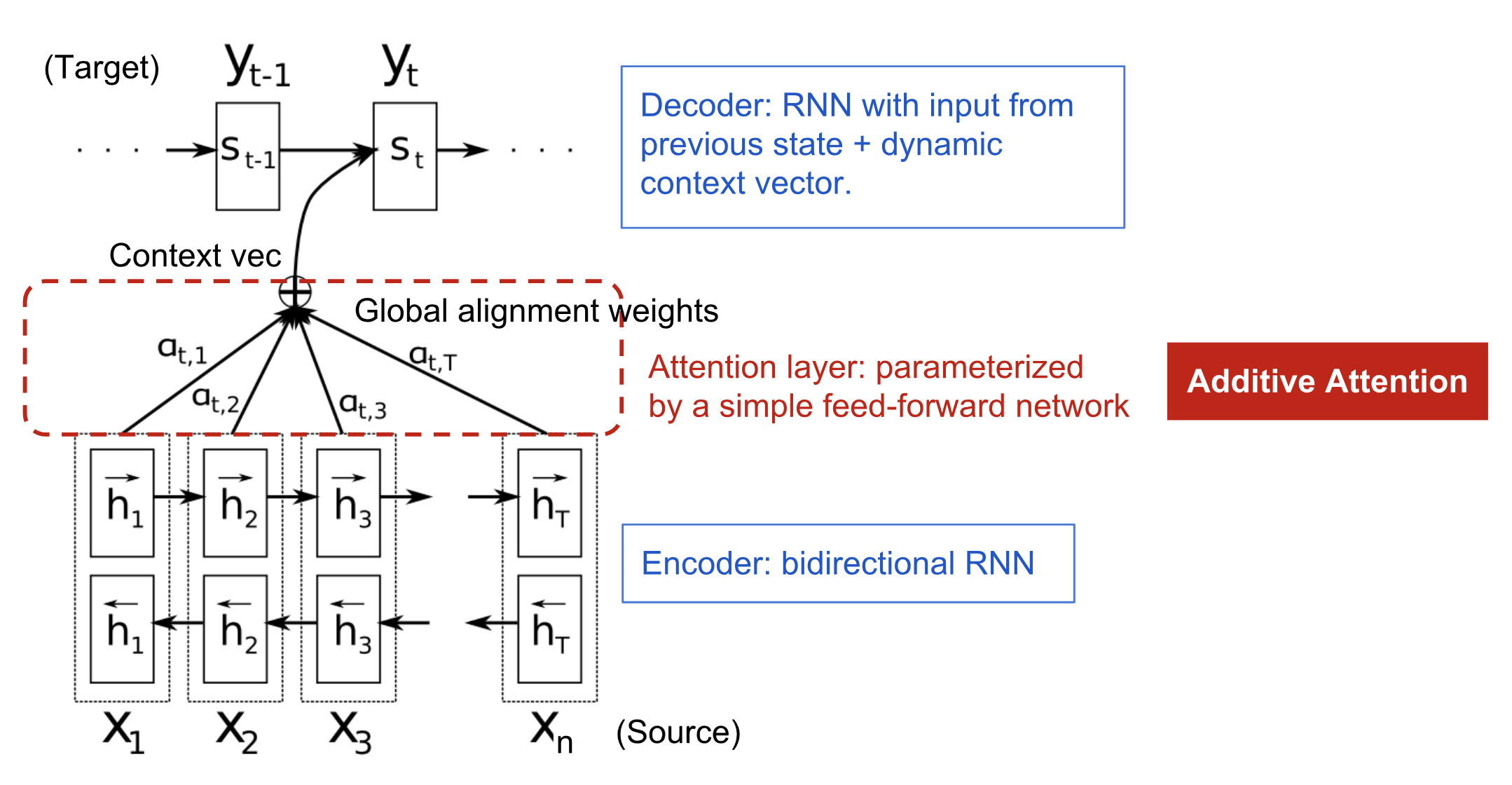 The encoder-decoder model with additive attention mechanism in
The encoder-decoder model with additive attention mechanism in
Neural Machine Translation by Jointly Learning to Align and Translate
Now let's define the attention mechanism. Say, we have a source sequence \(\mathbf{x}\) of length \(n\)
and try to output a target sequence \(\mathbf{y} \) of lenfth \(m\) (variables in bold indicate that they are vectors):
\[
\,\\
\begin{aligned}
\mathbf{x} &= [x_1, x_2, \dots, x_n] \\
\mathbf{y} &= [y_1, y_2, \dots, y_m]
\end{aligned}
\,\\
\,\\
\]
The encoder is a bidirectional RNN with a forward hidden state \(\overrightarrow{h}_i \) and a backward one \(\overleftarrow{h}_i\).
A simple concatenation of two represents the encoder state.
\[
\,\\
h_i = [\overrightarrow{h}_i^\top; \overleftarrow{h}_i^\top]^\top, i=1,\dots,n
\,\\
\,\\
\]
The decoder network has hidden state \(s_t = f(s_{t-1}, \, y_{t-1}, \, c_t ) \)
for the output word at position \(t\, (t = 1, \, \dots, \, m) \),
where the
context vector \(c_t = \sum_{i=1}^n \alpha_{t,i} \, h_i \)
is a sum of hidden states of the input sequence, weighted by alignment scores.
The alignment model assigns a score \(\alpha_{t,i}\) to the pair of input at position \(i\)
and output at position \(t\), \( (y_t, x_i) \), baed on how well they match.
\[
\,\\
a_{t,i} = \frac{\exp(\text{score}(s_{t-1}, h_i))}{\sum\limits_{i'=1}^n \exp(\text{score}(s_{t-1}, h_{i'}))}
\,\\
\,\\
\]
The set of \( {\alpha_{t,i}} \) are weights defining how much of each source hidden state
should be considered for each output.
In Bahdanau's paper, the alignment score \(\alpha\) is parameterized by a
feed-forward network with a single hidden layer, and this network is jointly
trained with other parts of the model.
The score function is therefore in the following form, given
that \(\tanh\) is used as the non-linear activation function:
\[
\,\\
\text{score}(s_t, h_i) = \mathbf{v}_a^\top \tanh(\mathbf{W}_a[s_t; h_i])
\,\\
\,\\
\]
where both \(\mathbf{v}_a\) and \(\mathbf{W_a}\) are weight matrices to be learned in the alignment model.
class BahdanauAttention(nn.Module):
def __init__(self, hidden_size):
super(BahdanauAttention, self).__init__()
self.Wa = nn.Linear(hidden_size, hidden_size)
self.Ua = nn.Linear(hidden_size, hidden_size)
self.Va = nn.Linear(hidden_size, 1)
def forward(self, query, keys):
# query: s_{t-1}
# keys: h_i
scores = self.Va(torch.tanh(self.Wa(query) + self.Ua(keys)))
scores = scores.squeeze(2).unsqueeze(1)
weights = F.softmax(scores, dim=-1)
context = torch.bmm(weights, keys)
return context, weights
Additive Attention taken from
NLP From Scratch: Translation with a Sequence to Sequence Network and Attention
The matrix of alignment scores is a nice byproduct to explicitly show the
correlation between source and target words.
 Alignment Matrix
Alignment Matrix
Self-attention, also known as intra-attention, is an
attention mechanism relating different positions
of a single sequence in order to compute a representation of the same sequence.
The long short-term memory network paper used self-attention to do machine reading.
In the example below, the self-attention mechanism enables us to learn the correlation between the current words and the previous part of the sentence.
 The current word is in red and the size of the blue shade indicates the activation level taken from
The current word is in red and the size of the blue shade indicates the activation level taken from
Long Short-Term Memory-Networks for Machine Reading
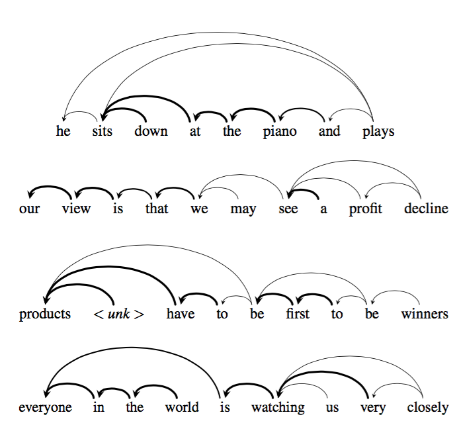 Examples of intra-attention
Examples of intra-attention
Long Short-Term Memory-Networks for Machine Reading
In the Show, Attend and Tell paper,
attention mechanism is applied to images to generate captions.
The image is first encoded by a CNN to extract features.
Then a LSTM decoder consumes the convolution features to produce descriptive words one by one.
A visualization of the attention weights clearly shows which areas of the image the model is attending.
 Visualization of the attention for each generated word taken from
Visualization of the attention for each generated word taken from
Neural Image Caption Generation with Visual Attention
-
Soft Attention:
the alignment weights are learned and placed "softly" over all patches in the source image.
-
Hard Attention:
only selects one patch of the image to attent to at a time.
It presented a lot of improvements to the soft attention and make it possible to do seq2seq modeling without recurrent network units.
The transformer adopts the scaled dot-product attention:
the output is a weighted sum of the values, where the
weight assigned to each value is determined by the dot-product of the query with all the keys:
\[
\,\\
\text{Attention}(\mathbf{Q}, \mathbf{K}, \mathbf{V}) = \text{softmax}(\frac{\mathbf{Q}\mathbf{K}^\top}{\sqrt{n}})\mathbf{V}
\,\\
\,\\
\]
Rather than only computing the attention once, the multi-head mechanism runs through the scaled dot-product attention multiple times in parallel.
The independent attention outputs are simply concatenated and linearly transformed into the expected dimensions.
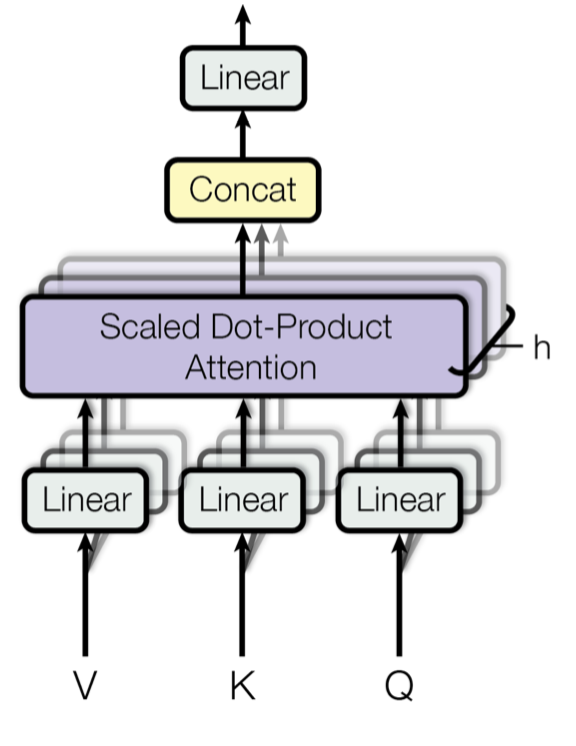 Multi-head scaled dot-product attention mechanism
Multi-head scaled dot-product attention mechanism
According to the paper, “multi-head attention allows the model to
jointly attend to information from different representation subspaces at different positions.
With a single attention head, averaging inhibits this.”
\[
\,\\
\begin{aligned}
\text{MultiHead}(\mathbf{Q}, \mathbf{K}, \mathbf{V}) &= [\text{head}_1; \dots; \text{head}_h]\mathbf{W}^O \\
\text{where head}_i &= \text{Attention}(\mathbf{Q}\mathbf{W}^Q_i, \mathbf{K}\mathbf{W}^K_i, \mathbf{V}\mathbf{W}^V_i)
\end{aligned}
\,\\
\,\\
\]
where \( \mathbf{W}^Q_i \), \( \mathbf{W}^K_i \), \( \mathbf{W}^V_i \), and \( \mathbf{W}^O \) are parameter matrices to be learned.
The encoder generates an attention-based representation with capability to locate a specific piece of information.
Each layer has a multi-head self-attention layer and a simple position-wise fully connected feed-forward network.
Each sub-layer adopts a residual connection and a layer normalization.
The encoder layer can be stacked \(N\) times because every sub-layer outputs the same dimension of \(d_{model} = 512\).
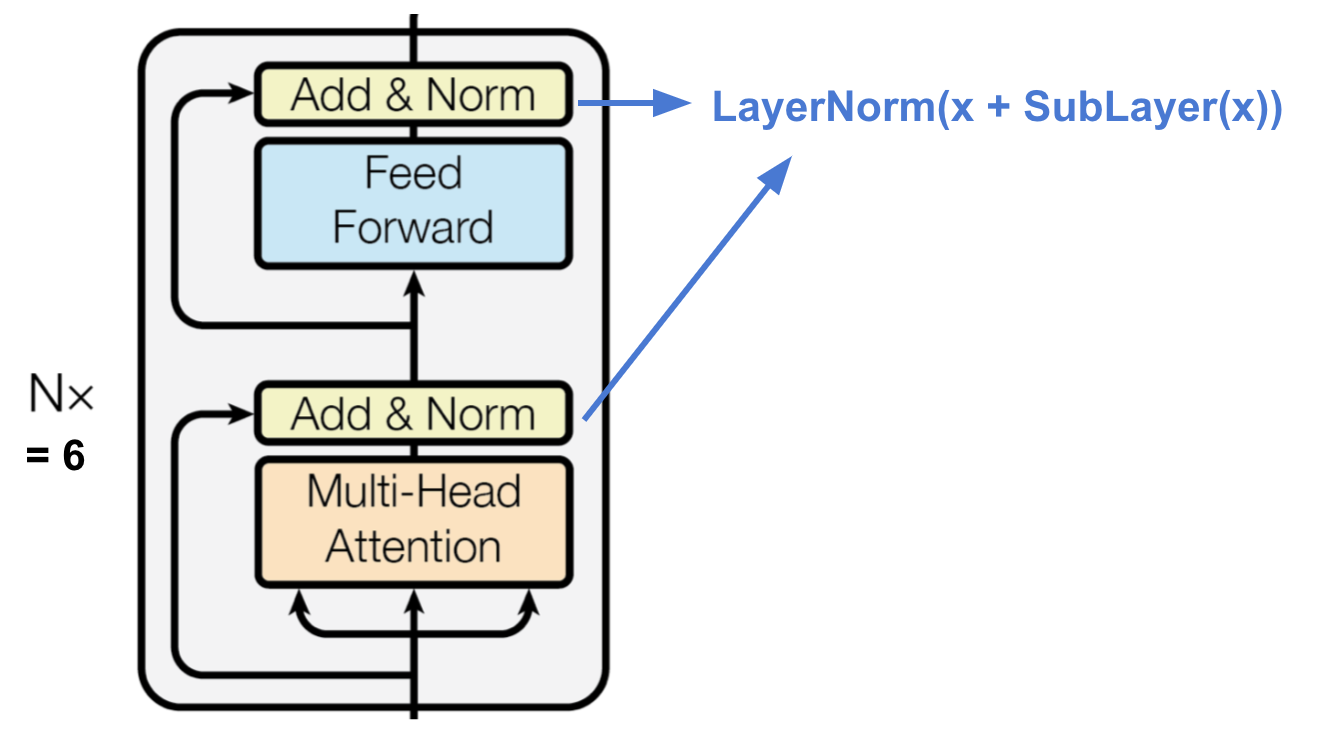 The transformer's encoder
The transformer's encoder
Each decoder layer consists of three sub-layers:
(1) a masked multi-head self-attention mechanism,
(2) a multi-head cross-attention mechanism, and
(3) a position-wise fully connected feed-forward network.
Similar to the encoder, each sub-layer adopts a residual connection and a layer normalization.
The first masked multi-head self-attention mechanism is modified to prevent positions from attending to subsequent positions,
as we don't want to look into the future of the target sequence when predicting the current position.
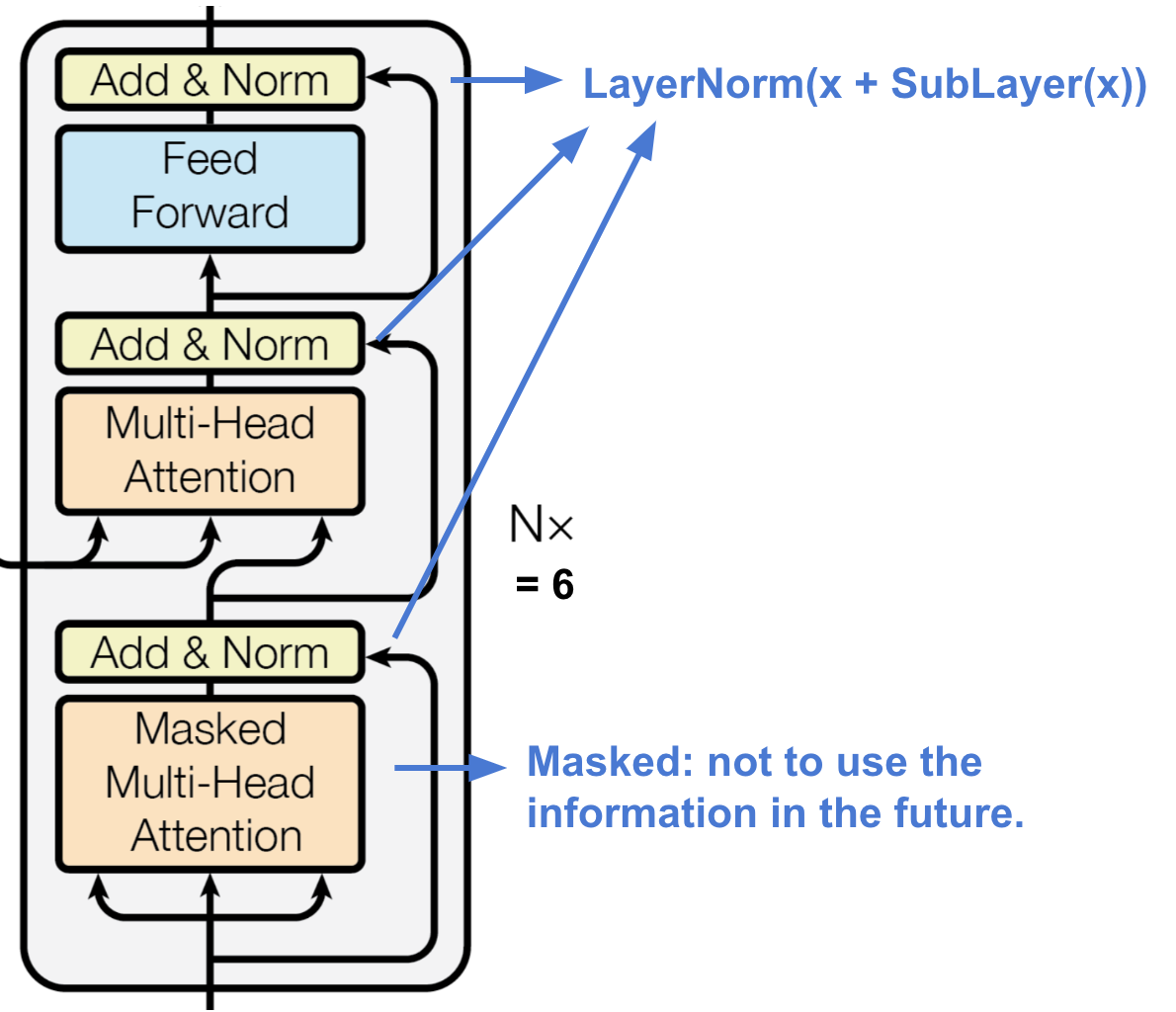 The transformer's decoder
The transformer's decoder
Both the source and target sequences first go through embedding layers to produce data of the same dimension \(d_{model} = 512 \).
To preserve the position information, a sinusoid-wave-based positional encoding is applied and summed with the embedding output.
A softmax and linear layer are added to the final decoder output.
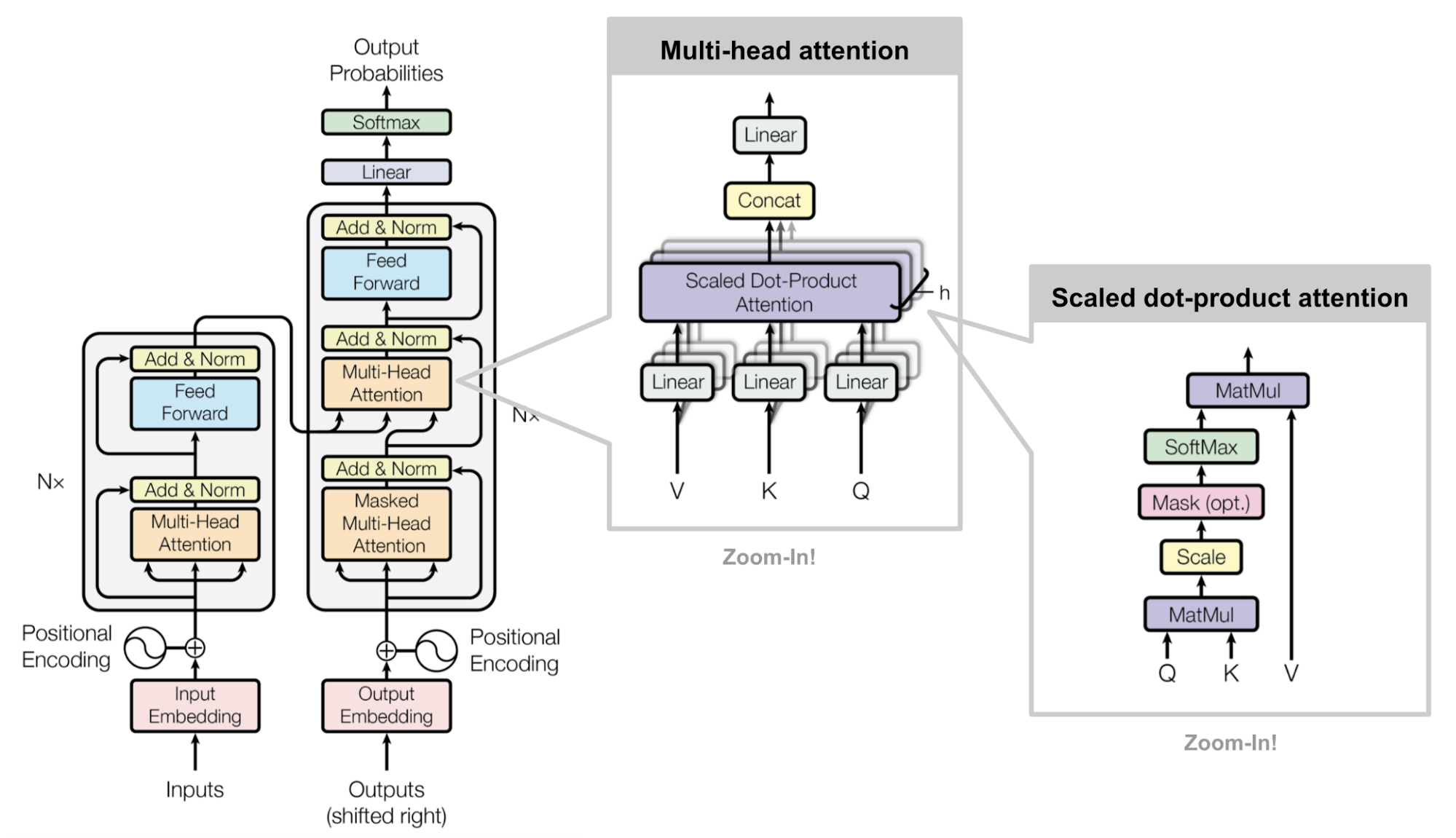 The full model architecture of the transformer
The full model architecture of the transformer